Java8函数式编程原理剖析
关于Lambda表达式
本质上,在java中的lambda表达式就是对匿名函数的一种简化实现
底层,需要知道,Lambda表达式由虚拟机指令InvokeDynamic实现方法调用。而InvokeDynamic是JVM的一条字节码指令,其通过运行时动态解析出调用的方法,然后去执行该方法。
Java8中支持Lambda表达式的,通常会以@FunctionalInterface来进行修饰,用来检查是否符合函数接口规范。
知识点总结
以下是关于Java流式编程(Stream API)的高频面试题总结,涵盖底层原理和核心知识点:
一、基础概念
什么是Java Stream?它与集合(Collection)的区别?
- Stream是Java 8引入的API,用于对数据集合进行函数式操作(过滤、映射、聚合等)。
- 区别:
- 集合存储数据,Stream不存储数据,仅通过操作管道处理数据。
- Stream操作是延迟执行(Lazy)的,需终端操作触发。
- Stream支持并行处理,集合默认是串行的。
Stream的操作类型有哪些?
- 中间操作(Intermediate Operations):返回新的Stream(如
filter,map,sorted)。 - 终端操作(Terminal Operations):触发实际计算并关闭Stream(如
collect,forEach,reduce)。
- 中间操作(Intermediate Operations):返回新的Stream(如
什么是惰性求值(Lazy Evaluation)?
- 中间操作不会立即执行,而是记录操作链,直到终端操作触发时才一次性执行所有操作,避免不必要的计算。
二、底层原理
Stream的流水线(Pipeline)是如何构建的?
- Stream操作链通过
AbstractPipeline类实现,分为三个阶段:- 源(Source):如集合、数组生成
Head节点。 - 中间操作节点:每个操作生成新的
StatelessOp或StatefulOp节点。 - 终端操作:触发流水线执行,生成结果或副作用。
- 源(Source):如集合、数组生成
- Stream操作链通过
Spliterator的作用是什么?
- Spliterator(可分割迭代器)是Stream的底层数据源分割工具,负责:
- 遍历数据(
tryAdvance)。 - 分割数据为更小的块供并行处理(
trySplit)。 - 优化遍历(如批量遍历
forEachRemaining)。
- 遍历数据(
- Spliterator(可分割迭代器)是Stream的底层数据源分割工具,负责:
并行流(Parallel Stream)的底层实现原理?
- 并行流使用
ForkJoinPool(默认共用commonPool)分割任务,通过Spliterator将数据拆分为子任务并行处理,最终合并结果。 - 注意:线程安全问题需自行处理,并行不总是更快(需数据量大且无竞争)。
- 并行流使用
Stream的中间操作如何叠加?
- 中间操作通过
ReferencePipeline链式调用,每个操作生成一个新的Stage节点,保存操作函数(如Predicate,Function),最终形成双向链表结构。
- 中间操作通过
三、性能与优化
Stream.forEach和for循环的性能差异?- 简单操作下,
for循环通常更快(无函数调用开销);复杂链式操作时Stream可能更高效(如并行处理)。 - 注意:Stream的优势在于代码简洁和并行能力,而非绝对性能。
- 简单操作下,
如何避免Stream的自动装箱开销?
- 使用原始类型特化流:
IntStream、LongStream、DoubleStream。
- 使用原始类型特化流:
Stateful和Stateless中间操作的区别?
- Stateless:无状态,操作独立处理每个元素(如
filter,map)。 - Stateful:需维护状态,可能影响并行性能(如
distinct,sorted,limit)。
- Stateless:无状态,操作独立处理每个元素(如
四、高频扩展问题
Stream.peek和Stream.map的区别?peek是中间操作,用于调试(无返回值),map将元素转换为新值。
Stream.reduce和Stream.collect的区别?reduce用于不可变聚合(如求和),collect用于可变聚合(如收集到集合)。
如何实现自定义收集器(Collector)?
- 实现
Collector接口,定义supplier(容器)、accumulator(累加)、combiner(合并)、finisher(转换)和characteristics(特性)。
- 实现
并行流的线程池如何配置?
- 默认使用
ForkJoinPool.commonPool(),可通过系统属性java.util.concurrent.ForkJoinPool.common.parallelism调整线程数,或提交任务到自定义线程池。
- 默认使用
五、底层源码分析(加分项)
- 流水线执行流程:终端操作触发
AbstractPipeline.evaluate方法,根据并行标志选择TerminalOp(如ForEachOp)执行。 - 短路操作优化:
findFirst、limit等操作通过Sink.cancellationRequested提前终止计算。 - 并行流合并策略:
ReduceOps中通过combiner函数合并子任务结果。
六、注意事项
- 避免副作用:Stream操作应是无状态的,禁止在
forEach中修改外部变量。 - 并行流慎用:数据量小或操作简单时,并行可能更慢;共享变量需同步。
- 关闭资源:
BaseStream.onClose()可注册关闭钩子(如文件流)。
掌握以上内容,可覆盖90%的Java流式编程面试考点,重点关注底层原理(如Spliterator、ForkJoinPool)和性能优化点。
示例代码
本文用到的所有示例代码,位于:Github:CoreJavaSample
Stream的定义
- 在 Java8 之前,我们通常是通过 for 循环或者 Iterator 迭代来重新排序合并数据,又或者通过重新定义 Collections.sorts 的 Comparator 方法来实现,这两种方式对于大数据量系统来说,效率并不是很理想。
- Java8 中添加了一个新的接口类 Stream,他和我们之前接触的字节流概念不太一样,Java8 集合中的 Stream 相当于高级版的 Iterator,他通过 Lambda 表达式对集合进行各种非常便利、高效的聚合操作(Aggregate Operation),或者大批量数据操作 (Bulk Data Operation)。
Stream的原理
可以认为,将要处理的元素看做一种流,流在管道中传输,并且可以在管道的节点上处理,包括过滤筛选、去重、排序、聚合等。元素流在管道中进过中间操作的处理,最后由最终操作得到前面处理的结果。
来看一个简单的例子,从代码来看,使用了JavaStream的代码,确实要简洁很多:
【备注】:先打个预防针,在实际项目中,要非常清楚你的逻辑以及对Stream的使用场景,切莫盲目为了“炫技”来使用Stream。后文中会提到一些不正当使用stream带来的后果。
1 | /** |
Stream如何优化遍历
Stream的操作分类
Stream 的操作分为两大类:中间操作(Intermediate operations)和终结操作(Terminal operations)。
我们通常还会将中间操作称为懒操作,也正是由这种懒操作结合终结操作、数据源构成的处理管道(Pipeline),实现了 Stream 的高效。
| 操作类型 | 详情 | 备注 |
|---|---|---|
| 中间操作 | 只对操作进行了记录,即只会返回一个流,不会进行计算操作 | 可以分为无状态(Stateless)与有状态(Stateful)操作,前者是指元素的处理不受之前元素的影响,后者是指该操作只有拿到所有元素之后才能继续下去。 |
| 终结操作 | 终结操作是实现了计算操作 | 可以分为短路(Short-circuiting)与非短路(Unshort-circuiting)操作,前者是指遇到某些符合条件的元素就可以得到最终结果,后者是指必须处理完所有元素才能得到最终结果。 |

Stream相关源码实现
先来看看几个类继承图:
其中:
- BaseStream 和 Stream 为最顶端的接口类。
- BaseStream 主要定义了流的基本接口方法,例如,spliterator、isParallel 等;
- Stream 则定义了一些流的常用操作方法,例如,map、filter 等
- ReferencePipeline 是一个结构类,他通过定义内部类组装了各种操作流。他定义了 Head、StatelessOp、StatefulOp 三个内部类,实现了 BaseStream 与 Stream 的接口方法
- Sink 接口是定义每个 Stream 操作之间关系的协议,他包含 begin()、end()、cancellationRequested()、accept() 四个方法
- ReferencePipeline 最终会将整个 Stream 流操作组装成一个调用链,而这条调用链上的各个 Stream 操作的上下关系就是通过 Sink 接口协议来定义实现的
Stream的操作叠加
管道结构通常是由 ReferencePipeline 类实现的,前面的类图Stream 包结构时,解释过 ReferencePipeline 包含了 Head、StatelessOp、StatefulOp 三种内部类。
这几个内部类分别包含的作用如下表所示:
| 内部类 | 作用 |
|---|---|
| Head | 主要用来定义数据源操作,在我们初次调用 names.stream() 方法时,会初次加载 Head 对象,此时为加载数据源操作 |
| StatelessOp | 无状态中间操作 |
| StatefulOp | 有状态中间操作 |
| Stage | 在 JDK 中每次的中断操作会以使用阶段(Stage)命名 |
| AbstractPipeline | 用于生成一个中间操作 Stage 链表 |
其中:中间操作之后,此时的 Stage 并没有执行,而是通过 AbstractPipeline 生成了一个中间操作 Stage 链表;
当我们调用终结操作时,会生成一个最终的 Stage,通过这个 Stage 触发之前的中间操作,从最后一个 Stage 开始,递归产生一个 Sink 链。
Stream执行流程
一个简单的例子:
1 | public class ExecutionStep { |
你以为的流程可能是:
- 首先遍历一次集合,得到所有学生的年龄;
- 然后遍历一次 filter 得到的筛选后的集合;
- 获取年龄集合;
- 最后再从年龄集合中找到最大的年龄;
- 如果存在就打印到控制台
但是实际的流程是:
- students.stream() 方法将会调用集合类基础接口 Collection 的 Stream 方法;
- Stream 方法就会调用 StreamSupport 类的 Stream 方法,方法中初始化了一个 ReferencePipeline 的 Head 内部类对象;
- 再调用 filter 和 map 方法,这两个方法都是无状态的中间操作,所以执行 filter 和 map 操作时,并没有进行任何的操作,而是分别创建了一个 Stage 来标识用户的每一次操作;
- new StatelessOp 将会调用父类 AbstractPipeline 的构造函数,这个构造函数将前后的 Stage 联系起来,生成一个 Stage 链表:
- 当执行 max 方法时,会调用 ReferencePipeline 的 max 方法,此时由于 max 方法是终结操作,所以会创建一个 TerminalOp 操作,同时创建一个 ReducingSink,并且将操作封装在 Sink 类中。
- Java8 中的 Spliterator 的 forEachRemaining 会迭代集合,每迭代一次,都会执行一次 filter 操作,如果 filter 操作通过,就会触发 map 操作,然后将结果放入到临时数组 object 中,再进行下一次的迭代。完成中间操作后,就会触发终结操作 max。
看一看内部相关代码
- students.stream()方法将会调用集合类基础接口 Collection 的 Stream 方法
关联源码如下:StreamSupport.stream方法:1
2
3
4default Stream<E> stream() {
// spliterator()方法后文介绍,这里知道这个方法
return StreamSupport.stream(spliterator(), false);
}1
2
3
4
5
6
7public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
// 这里内部调用到AbstractPipeline构造器函数进行属性赋值
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
关于Spliterator
关于在idea中怎么调试
上面的例子我作了一点扩充
1 | // 配套生成 |
在idea中有个非常可视化的调试工具,可以方便的看出这个数据在stream流计算下的过程,可以很方便的观察每个步骤处理的结果:
点击调试面板的三个点:
在弹开的页面中选择“Trace Current Stream Chain”:
默认弹出的页面是: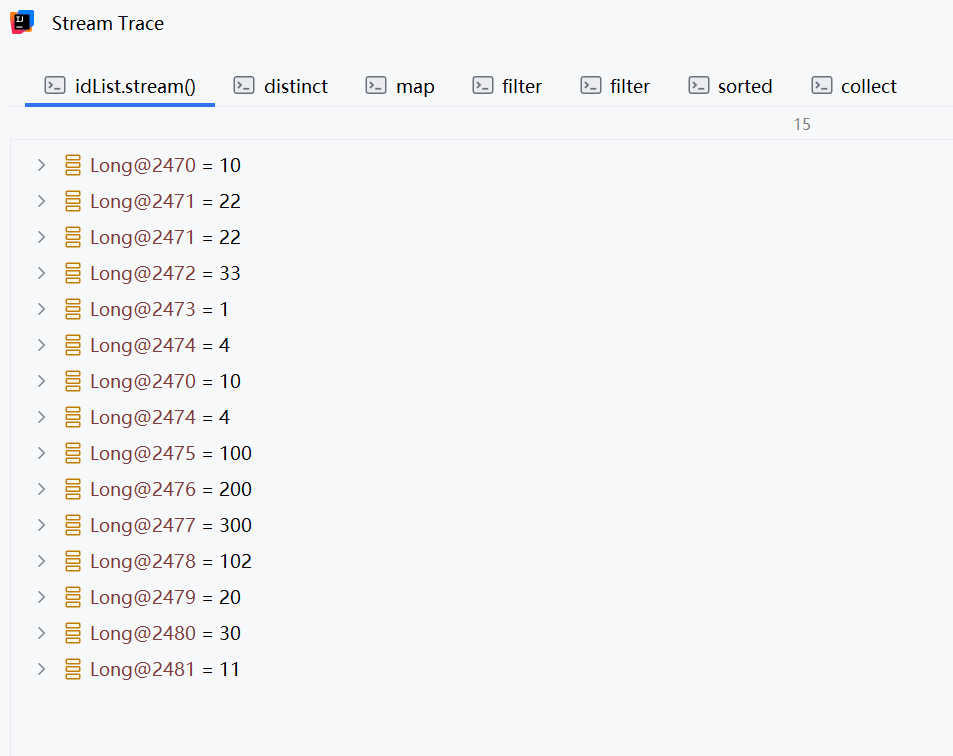
此时你可以选择不同的tab页来观察每个步骤的数据的变化情况,同时你也可以点击左下角的“Flat Mode”来改变试图: