细谈Dubbo
前言
XXX
知识点概括
以下是Dubbo相关的高频面试题总结,涵盖核心概念、架构设计、使用场景及进阶知识点:
Dubbo 核心原理总结
1. 核心架构
Dubbo 是一个分布式服务框架,基于 RPC(远程过程调用) 实现服务间的通信。其核心架构包含以下角色:
- Provider:服务提供者,暴露服务接口。
- Consumer:服务消费者,调用远程服务。
- Registry(注册中心):服务注册与发现(如 Zookeeper、Nacos)。
- Monitor:监控服务调用次数和耗时。
- Container:服务运行容器(如 Tomcat)。
2. 调用流程
- Provider 启动时向 Registry 注册服务。
- Consumer 启动时订阅 Registry 获取服务地址列表。
- Consumer 通过负载均衡策略选择 Provider 发起调用。
- Monitor 统计调用数据。
3. 关键机制
- SPI(Service Provider Interface):Dubbo 扩展性的核心,通过 SPI 动态加载实现类(如
Protocol、Cluster)。 - 服务暴露与引用:
- 暴露:Provider 将服务接口封装为
Invoker,通过Protocol暴露为 URL 格式。 - 引用:Consumer 通过
ProxyFactory生成远程服务的代理对象。
- 暴露:Provider 将服务接口封装为
- 负载均衡:支持
Random(默认)、RoundRobin、LeastActive、ConsistentHash等策略。 - 集群容错:
Failover(默认,失败重试)Failfast(快速失败)Failsafe(忽略异常)Failback(后台记录失败请求)Forking(并行调用多个节点)Broadcast(广播调用所有节点)
- 动态代理:使用 Javassist 或 JDK 动态代理生成 Consumer 的远程调用代理。
- 通信协议:默认
dubbo协议(单一长连接 + NIO),支持http、rmi、hessian等。
其它
1. Dubbo 的工作原理是什么?
- Provider 向注册中心注册服务,Consumer 订阅服务地址。
- Consumer 通过代理调用远程服务,底层通过 Netty 等框架进行网络通信。
- 调用过程涉及负载均衡、集群容错、序列化等机制。
2. Dubbo 的 SPI 和 Java SPI 有什么区别?
- Java SPI:通过
META-INF/services文件加载实现类,一次性加载所有扩展。 - Dubbo SPI:
- 按需加载,通过
@SPI注解指定默认实现。 - 支持自适应扩展(
@Adaptive注解动态生成适配类)。 - 支持扩展点自动包装(AOP 功能,如
ProtocolFilterWrapper)。
- 按需加载,通过
3. Dubbo 如何实现负载均衡?
- 随机(Random):按权重随机分配(默认)。
- 轮询(RoundRobin):按权重轮询调用。
- 最少活跃数(LeastActive):优先调用响应快的节点。
- 一致性哈希(ConsistentHash):相同参数的请求总是发送到同一 Provider。
4. Dubbo 的集群容错机制有哪些?
- Failover:失败后自动切换其他节点重试(默认)。
- Failfast:快速失败,直接抛出异常。
- Forking:并行调用多个节点,只要一个成功就返回。
- Broadcast:广播调用所有节点,任意一个报错则失败。
5. 服务暴露和引用的过程是怎样的?
- 暴露:
- 解析服务配置为
URL。 - 通过
ProxyFactory将服务接口转为Invoker。 - 通过
Protocol将Invoker暴露为 Exporter,并注册到 Registry。
- 解析服务配置为
- 引用:
- 从 Registry 获取 Provider 地址列表。
- 通过
Protocol创建Invoker。 - 通过
ProxyFactory生成服务代理对象。
6. Dubbo 如何实现动态代理?
- 默认使用 Javassist 生成字节码代理(性能高),可选 JDK 动态代理(依赖接口)。
7. Dubbo 支持哪些序列化协议?
- 默认使用 Hessian2,支持 JSON、Kryo、FST、Protobuf 等。可通过
<dubbo:protocol serialization="xxx">配置。
8. Dubbo 的线程模型是怎样的?
- Dispatcher:负责请求分发,如
all(所有消息派发到线程池)、direct(直接在 IO 线程处理)。 - ThreadPool:固定大小线程池(
fixed,默认)、缓存线程池(cached)等。
9. Dubbo 与 Spring Cloud 的区别?
- Dubbo:性能高,专注 RPC 和服务治理,需配合其他组件(如 Gateway、Config)构建完整微服务。
- Spring Cloud:一站式微服务解决方案(包含 Config、Zuul、Hystrix 等),基于 HTTP(REST),生态更完善。
10. 如何实现 Dubbo 服务路由和灰度发布?
- 路由规则:通过
<dubbo:route>或动态配置中心设置条件路由(如 IP 过滤)。 - 灰度发布:
- 使用版本号(
version)分组(group)隔离新旧服务。 - 结合负载均衡策略逐步切换流量。
- 使用版本号(
为什么Dubbo不推荐用redis作为注册中心
Dubbo 不推荐使用 Redis 作为注册中心,主要基于以下原因:
1. 数据一致性与可靠性问题
- Redis 的 Pub/Sub 机制不保证可靠性
Redis 的发布订阅(Pub/Sub)模式是“即发即忘”的,若消费者因网络波动或重启未及时订阅,会丢失服务变更通知,导致服务列表过期。- 对比 Zookeeper/Nacos:Zookeeper 的 Watcher 机制或 Nacos 的长轮询能可靠推送服务变更。
- 持久化与恢复机制不足
Redis 默认将数据存储在内存中,依赖 RDB/AOF 持久化,但在宕机恢复时可能丢失部分数据,导致注册信息不完整。- 对比 Zookeeper:通过 Zab 协议保证数据强一致性,节点重启后能快速恢复注册信息。
2. 服务发现功能的局限性
- 无原生心跳检测机制
Redis 不支持自动清理过期节点,需依赖外部逻辑(如定期设置 Key 过期时间)模拟心跳检测,实现复杂且易出错。- 对比 Zookeeper/Nacos:通过临时节点(Zookeeper)或健康检查(Nacos)自动剔除失效节点。
- 服务列表查询效率低
Redis 需通过KEYS或SCAN命令模糊匹配服务名,时间复杂度高(O(N)),可能引发性能问题。- 对比 Zookeeper:通过树形目录结构直接定位服务节点,查询效率高(O(1))。
3. 高可用方案的复杂性
- Redis Cluster/Sentinel 的运维成本高
需额外部署 Redis Sentinel 或 Cluster 实现高可用,配置复杂且对运维经验要求高。- 对比 Nacos:内置 Raft 协议,开箱即用,无需额外配置高可用组件。
- 脑裂风险
Redis Cluster 在分区故障时可能发生脑裂,导致注册信息不一致。- 对比 Zookeeper:通过 Zab 协议规避脑裂问题,保证集群一致性。
4. 性能与扩展性瓶颈
- 高频写操作压力
Dubbo 服务频繁注册/注销(如秒级心跳)会产生大量写入请求,Redis 的内存和网络带宽可能成为瓶颈。- 对比 Zookeeper/Nacos:通过批量合并写入和异步化设计优化性能。
- 连接数限制
Redis 的单节点连接数有限(默认 10000),大规模集群中可能因 Provider/Consumer 过多导致连接耗尽。- 对比 Nacos:支持横向扩展,无单点连接数限制。
5. 社区支持与生态兼容性
非主流方案,社区验证不足
Dubbo 官方推荐 Zookeeper、Nacos、Consul 等注册中心,Redis 作为注册中心的实践案例较少,潜在问题可能未被充分暴露。- 案例风险:例如 Redis 的 Lua 脚本兼容性问题、集群模式下的跨 Slot 访问限制等。
功能迭代滞后
Dubbo 对 Redis 注册中心的优化优先级低,新特性(如元数据管理、权重路由)可能无法及时支持。
总结:推荐方案
- 中小规模集群:优先选择 Nacos(易用性高,功能全面)。
- 强一致性场景:选择 Zookeeper(CP 设计,适合金融级场景)。
- 云原生环境:考虑 Kubernetes Service 或 Consul(与容器化部署天然契合)。
若必须使用 Redis,需自行实现以下关键功能:
- 可靠的心跳检测与服务自动剔除。
- 服务变更的可靠通知机制(如双重验证 + 定时全量拉取)。
- 高可用集群部署与脑裂规避方案。
Dubbo框架总览
1. 服务暴露与引用
- 服务暴露:服务提供者通过配置文件或注解将服务接口暴露,Dubbo 将其注册到注册中心(如 Zookeeper)。
- 服务引用:消费者从注册中心获取服务提供者地址,通过动态代理生成远程服务代理对象,进行远程调用。
2. 注册中心
- 提供者和消费者通过注册中心进行服务发现,注册中心记录服务提供者的地址和元数据,消费者订阅所需服务。
3. 远程调用
- 通信协议:Dubbo 支持多种协议(如 Dubbo、HTTP),默认使用 Dubbo 协议,基于 Netty 实现高效通信。
- 负载均衡:提供多种负载均衡策略(如随机、轮询),确保请求均匀分布到多个提供者。
- 集群容错:提供多种容错机制(如 Failover、Failfast),确保调用失败时自动重试或快速失败。
4. 监控与管理
- Dubbo 提供丰富的监控和管理功能,支持通过管理控制台查看服务状态、调用统计等。
5. 扩展机制
- Dubbo 通过 SPI 机制支持高度扩展,允许用户自定义协议、负载均衡策略等组件。
6. 服务治理
- 提供流量控制、服务降级、动态配置等功能,帮助系统在高并发下保持稳定。
Dubbo服务注册与发现过程
Dubbo 的启动与注册流程是服务提供者和消费者在分布式系统中协同工作的关键步骤。
注册发现整体流程如下图所示: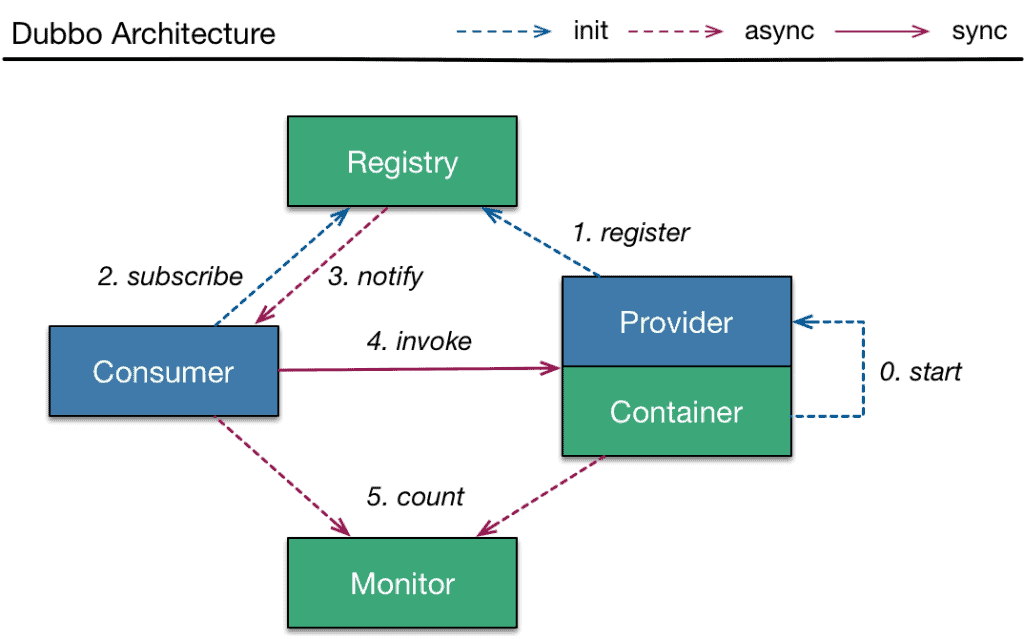
以下是 Dubbo 启动与注册的详细流程:
1. 服务提供者启动与注册流程
1.1 服务提供者启动
- 加载配置:
- 服务提供者通过 XML、注解或 API 方式加载 Dubbo 配置,包括服务接口、协议、注册中心等信息。
- 示例 XML 配置:
1
2
3<dubbo:service interface="com.example.DemoService" ref="demoService" />
<dubbo:protocol name="dubbo" port="20880" />
<dubbo:registry address="zookeeper://127.0.0.1:2181" />
- 初始化 Spring 容器:
- 如果使用 Spring,Dubbo 会通过 Spring 容器加载配置并初始化服务。
- 暴露服务:
- Dubbo 根据配置将服务接口暴露为远程服务。
- 使用
ServiceConfig类解析服务配置,生成服务的 URL。 - 示例 URL:
1
dubbo://192.168.1.1:20880/com.example.DemoService?version=1.0.0
- 启动 Netty 服务器:
- Dubbo 默认使用 Netty 作为通信框架,启动 Netty 服务器监听指定端口。
- 注册服务到注册中心:
- 将服务的 URL 注册到注册中心(如 Zookeeper)。
- 注册中心会记录服务提供者的地址和元数据。
- 示例 Zookeeper 节点:
1
/dubbo/com.example.DemoService/providers/dubbo://192.168.1.1:20880/com.example.DemoService
- 服务提供者启动完成:
- 服务提供者启动后,等待消费者调用。
1.2 服务提供者注册流程
- 生成服务 URL:
- 根据配置生成服务的 URL,包含协议、IP、端口、接口名、版本等信息。
- 连接注册中心:
- 服务提供者与注册中心建立连接(如 Zookeeper 客户端连接 Zookeeper 服务器)。
- 创建注册节点:
- 在注册中心创建临时节点(Zookeeper 的临时节点),存储服务提供者的 URL。
- 心跳维持:
- 服务提供者定期向注册中心发送心跳,维持节点的存活状态。
2. 服务消费者启动与订阅流程
2.1 服务消费者启动
- 加载配置:
- 服务消费者通过 XML、注解或 API 方式加载 Dubbo 配置,包括服务接口、注册中心等信息。
- 示例 XML 配置:
1
2<dubbo:reference id="demoService" interface="com.example.DemoService" />
<dubbo:registry address="zookeeper://127.0.0.1:2181" />
- 初始化 Spring 容器:
- 如果使用 Spring,Dubbo 会通过 Spring 容器加载配置并初始化消费者。
- 订阅服务:
- 服务消费者向注册中心订阅所需的服务。
- 使用
ReferenceConfig类解析服务配置,生成订阅的 URL。
- 获取服务提供者列表:
- 注册中心返回服务提供者的地址列表。
- 示例 Zookeeper 节点:
1
/dubbo/com.example.DemoService/providers
- 创建代理对象:
- Dubbo 根据服务接口和提供者地址,动态生成远程服务的代理对象。
- 消费者通过代理对象调用远程服务。
- 服务消费者启动完成:
- 服务消费者启动后,可以通过代理对象调用远程服务。
2.2 服务消费者订阅流程
- 生成订阅 URL:
- 根据配置生成订阅的 URL,包含接口名、版本等信息。
- 连接注册中心:
- 服务消费者与注册中心建立连接(如 Zookeeper 客户端连接 Zookeeper 服务器)。
- 订阅服务节点:
- 消费者订阅注册中心的服务节点(如 Zookeeper 的
/dubbo/com.example.DemoService/providers)。
- 消费者订阅注册中心的服务节点(如 Zookeeper 的
- 监听服务变化:
- 消费者监听服务节点的变化(如服务提供者上线或下线),动态更新本地服务提供者列表。
3. 服务调用流程
- 消费者发起调用:
- 消费者通过代理对象调用远程服务。
- 负载均衡:
- Dubbo 根据负载均衡策略(如随机、轮询)选择一个服务提供者。
- 网络通信:
- 消费者通过 Netty 客户端向服务提供者发送请求。
- 服务提供者处理请求:
- 服务提供者接收到请求后,调用本地实现类处理请求。
- 返回结果:
- 服务提供者将处理结果返回给消费者。
4. 服务下线与注销流程
- 服务提供者下线:
- 服务提供者关闭时,向注册中心发送下线通知。
- 注册中心删除对应的临时节点。
- 消费者更新列表:
- 消费者监听到服务提供者下线后,更新本地服务提供者列表。
总结
Dubbo 的启动与注册流程包括:
- 服务提供者:加载配置 → 暴露服务 → 启动 Netty → 注册到注册中心。
- 服务消费者:加载配置 → 订阅服务 → 获取提供者列表 → 创建代理对象。
- 服务调用:消费者通过代理对象调用远程服务,Dubbo 负责负载均衡和网络通信。
- 服务下线:提供者下线时通知注册中心,消费者动态更新提供者列表。
请求调用过程
在 Dubbo 中,请求的调用链路涉及多个组件和步骤,从消费者发起请求到服务提供者处理请求并返回结果,整个过程是高度模块化和可扩展的。
总体调用流程如下图所示:
以下是 Dubbo 请求调用链路的详细流程:
1. 消费者端调用链路
1.1 发起调用
- 代理对象调用:
- 消费者通过 Dubbo 生成的代理对象调用远程服务。
- 代理对象是 Dubbo 通过动态代理技术生成的,封装了远程调用的逻辑。
- 负载均衡:
- Dubbo 根据配置的负载均衡策略(如随机、轮询、一致性哈希等),从服务提供者列表中选择一个目标提供者。
- 集群容错:
- 如果调用失败,Dubbo 会根据配置的集群容错策略(如 Failover、Failfast、Failsafe 等)进行重试或快速失败。
- 过滤器链:
- 请求会经过一系列过滤器(Filter),用于实现日志记录、权限校验、参数验证等功能。
- 过滤器链是 Dubbo 的可扩展点,用户可以通过 SPI 机制自定义过滤器。
- 序列化:
- 请求参数会被序列化为二进制数据,Dubbo 支持多种序列化协议(如 Hessian、Kryo、JSON 等)。
- 网络传输:
- 序列化后的数据通过 Netty 或其他网络框架发送到服务提供者。
2. 网络传输
- 协议封装:
- Dubbo 将请求数据封装为协议消息,默认使用 Dubbo 协议。
- 协议消息包括请求头(如请求 ID、序列化方式)和请求体(如方法名、参数)。
- 网络通信:
- 消费者通过 Netty 客户端将协议消息发送到服务提供者。
3. 服务提供者端调用链路
3.1 接收请求
- 网络接收:
- 服务提供者通过 Netty 服务器接收请求数据。
- 协议解析:
- 解析协议消息,提取请求头(如请求 ID、序列化方式)和请求体(如方法名、参数)。
- 反序列化:
- 将二进制数据反序列化为 Java 对象。
- 过滤器链:
- 请求会经过一系列过滤器(Filter),用于实现日志记录、权限校验、参数验证等功能。
- 查找服务实现:
- 根据请求中的接口名和方法名,查找本地服务实现类。
- 调用本地服务:
- 通过反射调用本地服务实现类的方法。
- 处理业务逻辑:
- 服务提供者执行业务逻辑,生成结果。
3.2 返回响应
- 序列化:
- 将处理结果序列化为二进制数据。
- 协议封装:
- 将响应数据封装为协议消息,包括响应头(如请求 ID、状态码)和响应体(如结果数据)。
- 网络传输:
- 通过 Netty 服务器将响应消息发送回消费者。
4. 消费者端接收响应
- 网络接收:
- 消费者通过 Netty 客户端接收响应数据。
- 协议解析:
- 解析协议消息,提取响应头(如请求 ID、状态码)和响应体(如结果数据)。
- 反序列化:
- 将二进制数据反序列化为 Java 对象。
- 返回结果:
- 将结果返回给消费者调用方。
5. 调用链路中的关键组件
5.1 过滤器(Filter)
- 过滤器是 Dubbo 的可扩展点,用于在调用链路上插入自定义逻辑。
- 常见的过滤器包括:
- 日志过滤器:记录请求和响应的日志。
- 权限过滤器:校验调用方的权限。
- 限流过滤器:限制请求的速率。
5.2 负载均衡(LoadBalance)
- 负责从多个服务提供者中选择一个目标提供者。
- 常见的负载均衡策略包括:
- 随机(Random):随机选择一个提供者。
- 轮询(RoundRobin):按顺序选择提供者。
- 一致性哈希(ConsistentHash):根据请求参数哈希选择提供者。
5.3 集群容错(Cluster)
- 负责处理调用失败的情况。
- 常见的容错策略包括:
- Failover:失败后重试其他提供者。
- Failfast:快速失败,直接抛出异常。
- Failsafe:忽略错误,返回空结果。
5.4 序列化与反序列化
- 负责将 Java 对象转换为二进制数据,以及将二进制数据转换为 Java 对象。
- 常见的序列化协议包括:
- Hessian:默认的序列化协议。
- Kryo:高性能的序列化协议。
- JSON:易于调试的文本协议。
6. 调用链路示例
以下是一个简化的调用链路示例:
- 消费者调用代理对象。
- 代理对象通过负载均衡选择一个服务提供者。
- 请求经过过滤器链,进行日志记录和权限校验。
- 请求被序列化并通过 Netty 发送到服务提供者。
- 服务提供者接收请求,反序列化并调用本地服务。
- 服务提供者处理业务逻辑并返回结果。
- 结果被序列化并通过 Netty 发送回消费者。
- 消费者接收结果并返回给调用方。
Dubbo对SPI的扩展
Dubbo 的 SPI(Service Provider Interface)机制是其扩展能力的核心,允许用户在不修改框架源码的情况下,通过自定义实现来扩展功能。Dubbo 的 SPI 机制在 Java 标准 SPI 的基础上进行了增强,提供了更灵活的功能。以下是 Dubbo SPI 机制的主要特点和实现方式:
1. Java 标准 SPI 的不足
Java 标准 SPI 的局限性包括:
- 一次性加载所有实现类:浪费资源。
- 不支持按需加载:无法根据条件选择具体实现。
- 缺乏配置能力:无法通过配置指定默认实现或优先级。
Dubbo 的 SPI 机制解决了这些问题,提供了更强的扩展能力。
2. Dubbo SPI 的核心设计
Dubbo 的 SPI 机制通过 @SPI 注解和配置文件实现扩展点的动态加载和管理。
2.1 @SPI 注解
- 用于标识一个接口为扩展点。
- 可以指定默认的实现类。
- 示例:
1
2
3
4
5// 默认使用 "dubbo" 实现
public interface Protocol {
void export(Invoker<?> invoker);
Invoker<?> refer(Class<?> type, URL url);
}
2.2 配置文件
- 扩展点的实现类需要在
META-INF/dubbo/目录下定义配置文件。 - 文件名为扩展点接口的全限定名,内容为
key=实现类全限定名。 - 示例:
1
2dubbo=org.apache.dubbo.rpc.protocol.dubbo.DubboProtocol
http=org.apache.dubbo.rpc.protocol.http.HttpProtocol
2.3 扩展点加载
- Dubbo 通过
ExtensionLoader类加载和管理扩展点。 - 示例:
1
Protocol protocol = ExtensionLoader.getExtensionLoader(Protocol.class).getExtension("dubbo");
3. Dubbo SPI 的高级特性
Dubbo 的 SPI 机制在基础功能上增加了许多高级特性,使其更灵活和强大。
3.1 自适应扩展点(Adaptive)
- 通过
@Adaptive注解实现动态选择扩展点实现。 - 根据 URL 参数或运行时条件决定使用哪个实现。
- 示例:
1
2
3
4
public class AdaptiveProtocol implements Protocol {
// 根据 URL 参数动态选择实现
}
3.2 自动包装(Wrapper)
- 支持对扩展点实现进行包装,类似 AOP 的机制。
- 可以在不修改原有实现的情况下,增加额外功能。
- 示例:
1
2
3
4
5
6
7
8
9
10
11public class ProtocolWrapper implements Protocol {
private Protocol protocol;
public ProtocolWrapper(Protocol protocol) {
this.protocol = protocol;
}
public void export(Invoker<?> invoker) {
// 增加额外逻辑
protocol.export(invoker);
}
}
3.3 自动激活(Activate)
- 通过
@Activate注解实现扩展点的条件激活。 - 可以根据 URL 参数或调用上下文动态激活某些扩展点。
- 示例:
1
2
3
4
public class TestFilter implements Filter {
// 在特定条件下激活
}
3.4 扩展点依赖注入
- Dubbo 支持对扩展点实现类中的依赖进行自动注入。
- 通过
setter方法或字段注入依赖的其他扩展点。 - 示例:
1
2
3
4
5
6public class MyProtocol implements Protocol {
private Transporter transporter;
public void setTransporter(Transporter transporter) {
this.transporter = transporter;
}
}
4. Dubbo SPI 的工作流程
- 加载扩展点:通过
ExtensionLoader加载指定接口的扩展点实现。 - 解析配置文件:读取
META-INF/dubbo/下的配置文件,获取扩展点实现类。 - 实例化扩展点:根据配置实例化扩展点实现类。
- 注入依赖:对扩展点实现类中的依赖进行自动注入。
- 包装扩展点:如果存在包装类,对扩展点进行包装。
- 返回扩展点实例:返回最终的扩展点实例。
5. Dubbo SPI 的优势
- 灵活性:支持动态选择扩展点实现。
- 可扩展性:通过包装和依赖注入,可以轻松扩展功能。
- 解耦:扩展点与具体实现解耦,便于维护和升级。
- 配置化:通过配置文件管理扩展点,无需修改代码。
总结
Dubbo 的 SPI 机制通过 @SPI、@Adaptive、@Activate 等注解和 ExtensionLoader 类,实现了高度灵活和可扩展的插件化架构。它不仅解决了 Java 标准 SPI 的不足,还提供了自适应扩展、自动包装、条件激活等高级特性,是 Dubbo 框架的核心设计之一。
Dubbo的泛化调用
Dubbo 的泛化调用是一种特殊的调用方式,允许消费者在不依赖服务接口的情况下调用远程服务。这种方式适用于动态调用、网关类场景或无法直接依赖服务接口的情况。以下是 Dubbo 泛化调用的原理总结:
1. 泛化调用的核心思想
泛化调用的核心思想是:消费者不需要依赖服务提供者的接口类,而是通过通用的方式描述服务名、方法名和参数,发起远程调用。
- 服务接口解耦:消费者无需引入服务提供者的接口 JAR 包。
- 动态调用:可以在运行时动态决定调用的服务和方法。
- 通用性:适用于网关、测试工具等需要动态调用服务的场景。
2. 泛化调用的实现原理
2.1 泛化接口
Dubbo 提供了一个通用的接口 GenericService,用于描述泛化调用的方法:
1 | public interface GenericService { |
method:调用的方法名。parameterTypes:方法参数的类型(全限定类名)。args:方法的参数值。
2.2 消费者端实现
配置泛化引用:
- 在消费者端配置泛化引用,指定服务接口为
GenericService。 - 示例 XML 配置:
1
<dubbo:reference id="genericService" interface="com.example.DemoService" generic="true" />
- 在消费者端配置泛化引用,指定服务接口为
发起泛化调用:
- 通过
GenericService的$invoke方法发起调用。 - 示例代码:
1
2GenericService genericService = (GenericService) context.getBean("genericService");
Object result = genericService.$invoke("sayHello", new String[]{"java.lang.String"}, new Object[]{"world"});
- 通过
2.3 服务提供者端实现
- 接收泛化请求:
- 服务提供者接收到请求后,解析方法名、参数类型和参数值。
- 反射调用本地服务:
- 通过反射调用本地服务实现类的方法。
- 将结果返回给消费者。
3. 泛化调用的参数处理
3.1 参数类型
- 参数类型需要传递全限定类名(如
java.lang.String)。 - Dubbo 会根据参数类型反序列化参数值。
3.2 参数值
- 参数值可以是基本类型、POJO 对象或 Map。
- 如果参数是 POJO 对象,可以使用 Map 代替,Dubbo 会自动将 Map 转换为 POJO。
3.3 复杂对象处理
- 对于复杂对象(如嵌套 POJO),可以使用
Map<String, Object>描述对象结构。 - 示例:
1
2
3
4Map<String, Object> person = new HashMap<>();
person.put("name", "John");
person.put("age", 30);
Object result = genericService.$invoke("savePerson", new String[]{"com.example.Person"}, new Object[]{person});
4. 泛化调用的使用场景
4.1 网关类应用
- 网关类应用需要动态调用多个服务,无法直接依赖所有服务的接口。
- 通过泛化调用,网关可以根据请求动态决定调用的服务和方法。
4.2 测试工具
- 测试工具需要调用不同的服务进行测试,泛化调用可以避免为每个服务编写特定的测试代码。
4.3 动态服务调用
- 在某些场景下,服务和方法需要在运行时动态决定,泛化调用提供了灵活的调用方式。
5. 泛化调用的优缺点
5.1 优点
- 解耦:消费者无需依赖服务提供者的接口。
- 灵活:支持动态调用,适用于网关和测试工具。
- 通用性:可以调用任意服务和方法。
5.2 缺点
- 性能开销:反射调用和参数转换会带来一定的性能开销。
- 易用性:需要手动指定方法名和参数类型,使用不如直接调用接口方便。
- 类型安全:由于参数类型是字符串,容易出错且不易调试。
6. 示例代码
6.1 消费者端
1 | // 获取泛化引用 |
6.2 服务提供者端
1 | public class DemoServiceImpl implements DemoService { |
总结
Dubbo 的泛化调用通过 GenericService 接口实现,允许消费者在不依赖服务接口的情况下动态调用远程服务。其核心原理是通过反射和参数转换实现方法调用,适用于网关、测试工具等需要动态调用的场景。尽管泛化调用具有灵活性和通用性,但也存在性能开销和类型安全问题,需根据具体场景谨慎使用。
常见问题及解决办法
Dubbo 常见问题及解决方案总结
1. 服务提供者未注册到注册中心
现象:消费者无法发现服务,调用时报 No provider available。
原因:
- 注册中心地址配置错误(如 Zookeeper/Nacos 地址、端口错误)。
- 服务提供者未正确暴露接口(
@Service注解缺失或配置错误)。 - 网络问题(防火墙、端口未开放)。
解决:
- 检查 Provider 的
application.yml或 XML 配置:dubbo: registry: address: zookeeper://192.168.1.100:2181 protocol: name: dubbo port: 20880 - 查看 Provider 启动日志,确认是否输出
Export service ... url: dubbo://...。 - 使用
telnet测试注册中心连通性:telnet 192.168.1.100 2181
2. 服务调用超时(TimeoutException)
现象:调用远程服务时报 Invoke remote method timeout。
原因:
- 服务端处理耗时过长,超过默认超时时间(默认 1 秒)。
- 网络延迟或消费者-提供者配置不一致(如超时时间、版本号)。
解决:
- 调整超时时间:
或在dubbo: consumer: timeout: 3000 # 消费者全局超时(单位:ms) provider: timeout: 5000 # 提供者全局超时@Reference注解中指定:@Reference(timeout = 3000) private UserService userService; - 优化服务端性能(如异步化、缓存、SQL 优化)。
- 使用 异步调用 避免阻塞:
CompletableFuture<User> future = userService.getUserAsync(id); future.whenComplete((user, ex) -> { ... });
3. 循环依赖问题
现象:服务 A 依赖服务 B,服务 B 又依赖服务 A,导致启动失败。
解决:
- 重构代码:解耦服务,避免双向依赖。
- 懒加载:延迟依赖注入:
dubbo: consumer: lazy: true # 启用懒加载 - 使用
@Lazy注解:@Lazy @Reference private UserService userService;
4. 序列化错误(SerializationException)
现象:调用时报 Serialization failed 或 ClassNotFoundException。
原因:
- 接口参数或返回值未实现
Serializable。 - 消费者和提供者的接口类版本不一致(如字段增减)。
解决:
- 确保所有传输对象实现
Serializable:public class User implements Serializable { ... } - 保持接口的 版本号一致:
@Service(version = "1.0.0") public class UserServiceImpl implements UserService { ... }@Reference(version = "1.0.0") private UserService userService; - 使用兼容性强的序列化协议(如
kryo):dubbo: protocol: serialization: kryo
5. 线程池耗尽(RejectedExecutionException)
现象:高并发时服务端报 Thread pool is exhausted。
原因:默认线程池大小(200)不足。
解决:
- 调整服务端线程池:
dubbo: protocol: threads: 500 # 业务线程池大小 iothreads: 4 # IO线程数(Netty 工作线程) dispatcher: all # 所有请求派发到线程池 - 使用 消息队列 削峰填谷,降低瞬时压力。
- 启用 Sentinel 或 Hystrix 实现服务熔断降级。
6. 服务多版本灰度发布问题
现象:新旧版本服务共存时流量切换不精准。
解决:
- 版本号分组:
@Reference(version = "2.0.0", group = "gray") private UserService userService; - 路由规则:通过 Dubbo-Admin 动态配置路由:
key: userService priority: 1 conditions: - method=getUser => version=2.0.0 - 标签路由:结合注册中心(如 Nacos)的元数据实现灰度流量分配。
7. 依赖冲突(NoSuchMethodError/ClassNotFoundException)
现象:启动时报类找不到或方法不存在。
原因:Dubbo 依赖的第三方库(如 Netty、Zookeeper)版本与其他组件冲突。
解决:
- 使用
mvn dependency:tree分析依赖树,排除冲突包:<dependency> <groupId>org.apache.dubbo</groupId> <artifactId>dubbo-spring-boot-starter</artifactId> <exclusions> <exclusion> <groupId>io.netty</groupId> <artifactId>netty-all</artifactId> </exclusion> </exclusions> </dependency> - 统一父 POM 中的依赖版本。
通用排查工具
- Dubbo-Admin:查看服务列表、调用关系、动态配置路由规则。
- Telnet 调试:直接调用服务(需启用 Telnet 协议):
telnet 127.0.0.1 20880 > invoke UserService.getUser("123") - 日志级别调整:
logging: level: org.apache.dubbo: DEBUG